반응형
내용 출처 : 토끼군의 알 수 없는 세상
나는 zdnet을 잘 들여다 보진 않지만 아주 어쩌다가 쓸 만한 기사가 나오기 때문에 좋든 싫든 한 달에 너댓 번 쯤은 zdnet을 들어 가게 된다. 이번 기사도 (날짜는 상당히 지났건만;;) 그런 것 중 하나다.
zdnet 홈페이지에서 기사를 보시라. 아래는 기사 내용 중 실제로 구글을 사용하면서 편리할 것들을 (내 맘대로) 정리해 놓은 것이다. (본인이 쓸 목적도 있고, 혹시 필요할 사람이 있을까봐...)
구글의 컴퓨팅 규모
구글의 자산 가격(약 250 million $)을 기준으로 구글의 컴퓨팅 파워를 계산할 수 있다. 여기에서 나온 정보는 물론 실제 정보가 아니며 대략적인 범위만을 기재한 것이다:
참고로 top500.org의 2004년 6월 집계에 따르면 현재 최고 성능의 슈퍼 컴퓨터가 40 테라플롭스의 성능을 가지고 있다. (우리나라는 45위의 KAIST가 최고로, 5 테라플롭스의 성능을 가지고 있다. 비교되지 않는가;;;)
구글에서 좋은 검색 결과를 찾기 위한 방법
- 구글이 보여 주는 검색 결과는 항상 1000건 이내에서 잘라져서 나오기 때문에, 최대한 검색 집합을 줄이는 것이 중요하다.
- 단어는 기본적으로 and 연산으로 묶여진다. not 연산은 단어 앞에 -를 붙이는 것으로 구현된다.
- 중요한 단어를 최대한 앞에 놓는다. 구글의 검색 결과 출력은 단어 순서에 영향을 받는다.
- 일반적인 단어는 최대한 지운다. 책 이름 같은 데 포함될 경우 "..."로 확실하게 묶어 준다. 만약 꼭 필요하다면 단어 앞에 +를 붙여 주면 검색한다.
- 동일한 단어를 여러 개 나열할 경우 그 만큼 단어가 더 많이 들어 있는 페이지만을 검색하기 때문에 검색 집합을 좀 더 줄일 수 있다.
- 구글에서는 와일드카드를 사용할 수 있다. 단, 무조건 단어 단위기 때문에 "나의 살던 * * 산골" 식으로 단어들 대신으로만 쓰일 수 있다. (와일드 카드는 10단어 제약에 포함되지 않는다.)
- 메타 구문을 잘 활용하라. 아래에 그 리스트를 정리해 놓았다.
구글의 특수 구문
모든 메타구문은 blahblah:어쩌구 식으로 사용된다. 해당 메타구문에 not 연산을 적용할 경우 단어와 마찬가지로 -를 앞에 붙이면 된다. (-blahblah:어쩌구)
Julian Date는 기원전 4713년 1월 1일 이후 지난 날 수(GMT 기준)이다. 혹시나 UNIX Timestamp에 대해 알고 있다면, (timestamp - 946727935.816) / 86400 + 2451545라는 식으로 Julian Date를 얻을 수 있다. (이 글을 쓰는 시점에서 Julian date는 2453245.09이다.)
혹시나 HanIRC를 쓰는 분이 있다면 #perky 혹은 #tokigun 채널에서 종종 떠 다니는 토끼냥(본인이 만든 irc 봇-_-)에게 &-timestamp jd 2004 8 7 0 0 0과 같은 명령을 주면 Julian Date를 변환해서 보여 줄 것이다. 물론 토끼냥은 그렇게 자주 보이는 건 아니다 ;)
구글의 또 다른 기능
- 특수 구문 말고 문장의 앞뒤에 특정한 단어를 입력하면 특정한 종류의 검색을 자동으로 해 주는 기능이 있다. "단어"나 "용어"는 단어/용어 검색, "날씨"는 날씨, "주가"는 주가 및 기업 정보(그냥 종목코드만 써도 된다), "우편번호"는 우편번호를 알려 준다.
- 운 좋은 예감 버튼도 종종 괜찮을 때가 있다. :) 불여우에서 도메인이 아닌 엉뚱한 단어가 주소창에 들어 왔을 경우 기본적으로 구글의 운 좋은 예감으로 연결된다. (넷피아가 없어도 :)
- 계산기 기능도 있는데, 여기에 대해서는 google guide에 있는 페이지를 읽는 게 도움이 될 것이다. 간단한 사칙 연산부터, 단위 변환, 복소수 연산-_- 등이 가능하다.
구글 애플리케이션과 사이트
- 구글 툴바를 사용하면 브라우저(MSIE)에서 바로 구글 검색을 할 수 있다. 모질라/불여우에서는 GoogleBar라는 확장 기능을 대신 사용할 수 있다.
- 구글 데스크바를 사용하면 데스크탑에서 바로 구글 검색을 할 수 있다.
- google guide: 구글을 활용하는 많은 방법을 소개하고 있다.
- googlism: 구글에서 검색된 페이지를 바탕으로 구글이 특정 단어에 대해서 어떻게 정의내리고 있는 지(;;) 알아 볼 수 있다. 예를 들어서 빌 게이츠 같이...
- googlewhacking: 사전에 존재하는 특정한 두 단어의 조합으로 단 하나의 페이지 검색 결과만을 얻어 내는 놀이.
- Toogle: 구글 이미지 검색의 첫 결과를 ASCII 문자들로 변환해 준다. (저번에 소개한 적이 있음)
이거 말고 또 하나 더 있는데 이름을 까먹어서 찾을 수 조차 없었다... ;;; 마지막으로 Google Labs에서는 구글이 준비하고 있는 여러 가지 다른 서비스들을 구경해 볼 수 있다.
나는 zdnet을 잘 들여다 보진 않지만 아주 어쩌다가 쓸 만한 기사가 나오기 때문에 좋든 싫든 한 달에 너댓 번 쯤은 zdnet을 들어 가게 된다. 이번 기사도 (날짜는 상당히 지났건만;;) 그런 것 중 하나다.
zdnet 홈페이지에서 기사를 보시라. 아래는 기사 내용 중 실제로 구글을 사용하면서 편리할 것들을 (내 맘대로) 정리해 놓은 것이다. (본인이 쓸 목적도 있고, 혹시 필요할 사람이 있을까봐...)
구글의 컴퓨팅 규모
구글의 자산 가격(약 250 million $)을 기준으로 구글의 컴퓨팅 파워를 계산할 수 있다. 여기에서 나온 정보는 물론 실제 정보가 아니며 대략적인 범위만을 기재한 것이다:
랙: 539 - 899개 / 시스템: 47,432 - 79,112개 / CPU: 94,864 - 158,224개
프로세스 파워: 189,728 - 316,448GHz / 램: 94,864 - 158,224GB / 하드디스크: 3,705 - 6,180TB
전체 컴퓨팅 성능: 189 - 316 테라플롭스
프로세스 파워: 189,728 - 316,448GHz / 램: 94,864 - 158,224GB / 하드디스크: 3,705 - 6,180TB
전체 컴퓨팅 성능: 189 - 316 테라플롭스
참고로 top500.org의 2004년 6월 집계에 따르면 현재 최고 성능의 슈퍼 컴퓨터가 40 테라플롭스의 성능을 가지고 있다. (우리나라는 45위의 KAIST가 최고로, 5 테라플롭스의 성능을 가지고 있다. 비교되지 않는가;;;)
구글에서 좋은 검색 결과를 찾기 위한 방법
- 구글이 보여 주는 검색 결과는 항상 1000건 이내에서 잘라져서 나오기 때문에, 최대한 검색 집합을 줄이는 것이 중요하다.
- 단어는 기본적으로 and 연산으로 묶여진다. not 연산은 단어 앞에 -를 붙이는 것으로 구현된다.
- 중요한 단어를 최대한 앞에 놓는다. 구글의 검색 결과 출력은 단어 순서에 영향을 받는다.
- 일반적인 단어는 최대한 지운다. 책 이름 같은 데 포함될 경우 "..."로 확실하게 묶어 준다. 만약 꼭 필요하다면 단어 앞에 +를 붙여 주면 검색한다.
- 동일한 단어를 여러 개 나열할 경우 그 만큼 단어가 더 많이 들어 있는 페이지만을 검색하기 때문에 검색 집합을 좀 더 줄일 수 있다.
- 구글에서는 와일드카드를 사용할 수 있다. 단, 무조건 단어 단위기 때문에 "나의 살던 * * 산골" 식으로 단어들 대신으로만 쓰일 수 있다. (와일드 카드는 10단어 제약에 포함되지 않는다.)
- 메타 구문을 잘 활용하라. 아래에 그 리스트를 정리해 놓았다.
구글의 특수 구문
모든 메타구문은 blahblah:어쩌구 식으로 사용된다. 해당 메타구문에 not 연산을 적용할 경우 단어와 마찬가지로 -를 앞에 붙이면 된다. (-blahblah:어쩌구)
- allinanchor: 링크 텍스트(즉, a 태그로 묶인 텍스트)에서 검색
- allintext: 본문 안에서 검색
- allintitle: 제목 안에서 검색 (중요한 단어를 allintitle로 넣는 것이 좋다.)
- allinurl: URL 안에서 검색
- cache: 구글이 캐시하고 있는 페이지를 검색
- daterange: 페이지가 색인된 날짜를 지정한다. "<시작>-<끝>" 형태로 쓰며 반드시 Julian Date 형식으로 입력해야 한다. (뒤에서 설명)
- define: 영어 단어 정의를 검색한다. 한국어는 특수 구문이 없고 대신 "단어"나 "용어"를 앞뒤에 추가하면 된다.
- filetype: 파일 형식으로 검색한다. pdf, ps, xls, doc, rtf, ppt를 사용할 수 있다.
- info: 페이지의 정보를 보여 준다.
- link: 특정 URL로 링크를 건 페이지를 검색한다.
- related: 특정 URL과 비스무레한 페이지를 검색한다.
- site: 특정 사이트를 대상으로(해당 도메인 아래에 있는) 페이지를 검색한다.
- allintext: 본문 안에서 검색
- allintitle: 제목 안에서 검색 (중요한 단어를 allintitle로 넣는 것이 좋다.)
- allinurl: URL 안에서 검색
- cache: 구글이 캐시하고 있는 페이지를 검색
- daterange: 페이지가 색인된 날짜를 지정한다. "<시작>-<끝>" 형태로 쓰며 반드시 Julian Date 형식으로 입력해야 한다. (뒤에서 설명)
- define: 영어 단어 정의를 검색한다. 한국어는 특수 구문이 없고 대신 "단어"나 "용어"를 앞뒤에 추가하면 된다.
- filetype: 파일 형식으로 검색한다. pdf, ps, xls, doc, rtf, ppt를 사용할 수 있다.
- info: 페이지의 정보를 보여 준다.
- link: 특정 URL로 링크를 건 페이지를 검색한다.
- related: 특정 URL과 비스무레한 페이지를 검색한다.
- site: 특정 사이트를 대상으로(해당 도메인 아래에 있는) 페이지를 검색한다.
Julian Date는 기원전 4713년 1월 1일 이후 지난 날 수(GMT 기준)이다. 혹시나 UNIX Timestamp에 대해 알고 있다면, (timestamp - 946727935.816) / 86400 + 2451545라는 식으로 Julian Date를 얻을 수 있다. (이 글을 쓰는 시점에서 Julian date는 2453245.09이다.)
혹시나 HanIRC를 쓰는 분이 있다면 #perky 혹은 #tokigun 채널에서 종종 떠 다니는 토끼냥(본인이 만든 irc 봇-_-)에게 &-timestamp jd 2004 8 7 0 0 0과 같은 명령을 주면 Julian Date를 변환해서 보여 줄 것이다. 물론 토끼냥은 그렇게 자주 보이는 건 아니다 ;)
구글의 또 다른 기능
- 특수 구문 말고 문장의 앞뒤에 특정한 단어를 입력하면 특정한 종류의 검색을 자동으로 해 주는 기능이 있다. "단어"나 "용어"는 단어/용어 검색, "날씨"는 날씨, "주가"는 주가 및 기업 정보(그냥 종목코드만 써도 된다), "우편번호"는 우편번호를 알려 준다.
- 운 좋은 예감 버튼도 종종 괜찮을 때가 있다. :) 불여우에서 도메인이 아닌 엉뚱한 단어가 주소창에 들어 왔을 경우 기본적으로 구글의 운 좋은 예감으로 연결된다. (넷피아가 없어도 :)
- 계산기 기능도 있는데, 여기에 대해서는 google guide에 있는 페이지를 읽는 게 도움이 될 것이다. 간단한 사칙 연산부터, 단위 변환, 복소수 연산-_- 등이 가능하다.
구글 애플리케이션과 사이트
- 구글 툴바를 사용하면 브라우저(MSIE)에서 바로 구글 검색을 할 수 있다. 모질라/불여우에서는 GoogleBar라는 확장 기능을 대신 사용할 수 있다.
- 구글 데스크바를 사용하면 데스크탑에서 바로 구글 검색을 할 수 있다.
- google guide: 구글을 활용하는 많은 방법을 소개하고 있다.
- googlism: 구글에서 검색된 페이지를 바탕으로 구글이 특정 단어에 대해서 어떻게 정의내리고 있는 지(;;) 알아 볼 수 있다. 예를 들어서 빌 게이츠 같이...
- googlewhacking: 사전에 존재하는 특정한 두 단어의 조합으로 단 하나의 페이지 검색 결과만을 얻어 내는 놀이.
- Toogle: 구글 이미지 검색의 첫 결과를 ASCII 문자들로 변환해 준다. (저번에 소개한 적이 있음)
이거 말고 또 하나 더 있는데 이름을 까먹어서 찾을 수 조차 없었다... ;;; 마지막으로 Google Labs에서는 구글이 준비하고 있는 여러 가지 다른 서비스들을 구경해 볼 수 있다.
'Web' 카테고리의 다른 글
| 구글 애드센스 용어 (0) | 2006.03.18 |
|---|---|
| Picasa (0) | 2006.03.17 |
| 구글이 사이트 수집못하게 막기 (1) | 2006.02.17 |
| 피드한것이 깨질때. (1) | 2006.02.17 |
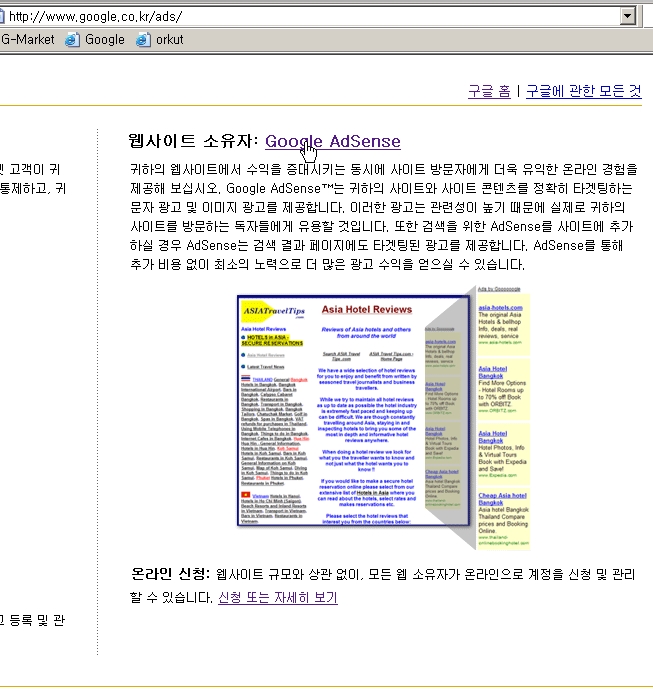
| 구글 애드센스를 달아보자. (0) | 2006.02.17 |







 invalid-file
invalid-file