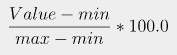반응형
큐넷에 올라온 정보처리기사 필기 출제기준을 PDF로 변환하여 게시한다.
정보처리기사 출제기준(2023.1.1._2025.12.31).pdf
0.23MB
정보처리기사 출제기준(2023.1.1._2025.12.31).hwp
0.08MB












'Programming' 카테고리의 다른 글
| [C#] wpf 프로젝트 빌드 시 exe파일에 dll 포함시켜서 빌드하기 (0) | 2023.10.17 |
|---|---|
| [C#] 구조체 - 바이트배열 간 데이터 변환 (0) | 2023.07.14 |
| 특정 범위내에서 값의 비율(%) 산출 공식 (0) | 2022.09.01 |
| [c#] JSON 내용을 Class화 시켜주는 사이트 (0) | 2022.08.10 |
| [c#] json을 DataTable로 한번에 변환 (0) | 2022.08.10 |